Tensor Factorization
 written by Rida Mirza
written by Rida MirzaTensor factorization refers to methods for decomposing multi-dimensional arrays, known as tensors, into simpler components. Tensors can model complex multidimensional datasets found in areas like neuroscience, computer vision, natural language processing, and more.
In this article, we will discuss about tensor factorization.
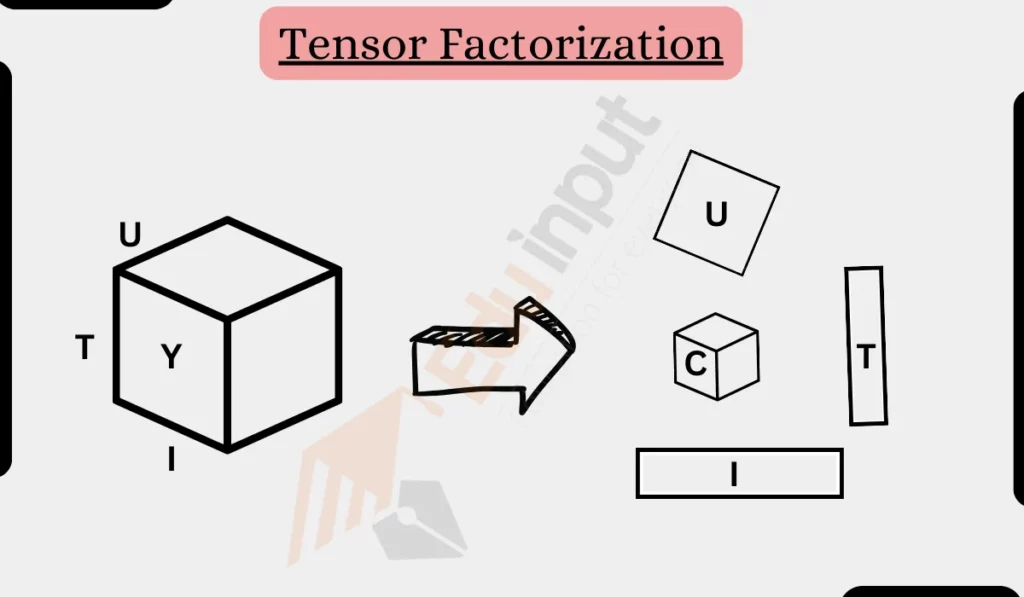
Key Methods for Tensor Factorization
- CANDECOMP/PARAFAC (CP) Decomposition: Factorizes a tensor into a sum of rank-one tensor components. Useful for identifying latent factors within the tensor.
- Tucker Decomposition: Decomposes a tensor into a core tensor multiplied by factor matrices along each mode. Captures interactions between modalities as well as latent factors.
- Tensor Train Decomposition: Represents a tensor by a sequence of third-order tensors that approximate the original tensor. Efficient for working with high-dimensional data.
Example of CANDECOMP/PARAFAC (CP) Decomposition
Given a 100x100x100 tensor X, CP decomposition factorizes it as:
X = ∑ A B C
Where A, B and C are 100×5 factor matrices. This approximates X as a sum of 5 rank-one tensors, revealing 5 latent factors that span the modes of X. The individual columns of A, B, C represent the factor loadings.
Example of Tucker Decomposition
Given the same 100x100x100 tensor X, Tucker decomposition expresses it as:
X = G x1 A x2 B x3 C
Where G is a 5x5x5 core tensor, and A, B and C are 100×5 factor matrices like before. This models interactions between the latent factors via G, while still identifying interpretable factors.
Also Read:
FAQS
What types of data are suited for tensor factorization?
Multi-modal, multi-dimensional datasets like MRI scans, video data and multi-language corpora.
What are the main advantages of tensor methods over matrix methods?
Ability to model multi-way structure and interactions, greater expressiveness.
How can the results of tensor factorization be interpreted?
The factors often relate to latent semantic or explanatory factors within the data

Leave a Reply